Member of Group ›
Toby Walsh: Az AI legrövidebb története
Yuval Noah Harari, Parmy Olson, Karen Hao és Bőgel György könyve után egy ötödik, szintén a mesterséges intelligenciával foglalkozó könyvet mutatok be a következőkben.
Harari általában írt az AI-ról és veszélyeiről, Olson a három gigamega cég (DeepMind, OpenAI, Anthropic) és alapító vezetőik (Demis Hassabis, Sam Altman, Dario Amodei) versenyét és az óriás techcégekbe való betagozódásukat mutatta be, Karen Hao az OpenAI, és vezetője, Sam Altman ellentmondásos karakterét járta körbe, Bőgel György pedig a gazdasági összefüggésekről értekezett.
Yuval Noah Harari: Nexus
Parmy Olson: Világuralom
Karen Hao: Az AI birodalma
Bőgel György: AI a gazdaságban
Miért foglalkozok ennyit ezzel ezzel a témával?
Persze, mint sok mindenre, erre is van egy hosszú és bonyolult válaszom, amit nem fogok leírni. Legyen elég annyi, hogy az emberiség teljes története során, még nem volt olyan invenció, amely ennyire rövid idő alatt, ilyen óriási mértékben változtatta volna meg (fogja megváltoztatni) a ma ismert világ egymásba fonódó szociális és gazdasági szövetét. Nyilván jelenleg még csak az alap infrastruktúra kialakítása zajlik, de vigyázó szemeinket a szingularitásra és az AGI-ra vetve, ez a hólabda egyre gyorsuló mozgással és tömeggel fogja letarolni az eddig ismert világgazdasági és szociális szabályrendszert.
AGI (Artificial General Intelligence)
Az AGI, magyarul teljes általános intelligencia, egy olyan AI rendszer, amely képes általános értelmi képességek tanúsítására, hasonlóan az emberi intelligenciához. Ez azt jelenti, hogy egy AGI képes feladatok széles körének elvégzésére, tanulásra, alkalmazkodásra, megértésre és kreativitásra, minden specifikus előzetes programozás nélkül. Ellentétben a jelenlegi mesterséges „szűk” intelligenciával (ANI), amelynek kompetenciája jól meghatározott feladatokra korlátozódik, egy AGI-rendszer képes a tudás általánosítására, a készségek területek közötti átvitelére, valamint új problémák megoldására anélkül, hogy feladatspecifikus átprogramozásra lenne szükség.
Szingularitás
Az AI szingularitás egy hipotetikus jövőbeli pont, amikor a mesterséges intelligencia eléri az emberi szintű intelligenciát, majd képessé válik önmaga folyamatos és robbanásszerű fejlesztésére. Az Anthropic hivatalos belső jelentése szerint a vállalat élesített szoftverkódjának (production codebase) több mint 80%-át már maga a Claude mesterséges intelligenciájuk írta. Ez a „fekete doboz” jelleg, persze hatalmas kockázatokat is hordoz, pl. két hete az Anthropic bejelentette, hogy az amerikai kormány utasítására azonnali hatállyal letiltja a két legfejlettebb mesterséges intelligencia-modelljét, a Fable 5-öt és a Mythos 5-öt valamennyi felhasználója számára. A nemzetbiztonsági aggályokra hivatkozó döntés új fejezetet nyitott a mesterséges intelligencia-iparág szabályozásában.
Valószínűleg ennek köszönhető, hogy három napja az amerikai kormányzat arra kérte az OpenAI-t is, hogy a hamarosan megjelenő GPT 5.6-os modelljét kizárólag néhány, állami jóváhagyással rendelkező partner számára tegye csak elérhetővé. Persze a techoptimista – disztópikus (Boom – Doom) tengelyen a szokott módon szóródnak a tudósok és a jövőkutatók, de az bizonyos, hogy a bárgyú és/vagy érdekalapú struccpolitika helyett preventíven kell foglalkoznunk a potenciális veszélyekkel is. (Hiszen roppant gyors folyamat ez és hatalmas hullámokat kelt majd az életünk számos területén.)
Toby Walsh: A mesterséges intelligencia legrövidebb története

A szerző, Toby Walsh az UNSW Sydney-i AI Institute vezető, díjazott tudósa és mesterséges intelligencia professzor az Új-Dél-Wales-i Egyetemen. Könyvének címe magyarul kissé esetlen, de ha ismerjük az eredeti sorozatot (The Shortest History of…) megértjük a bicegő hazai tükörfordítást. A könyv első mondata a következő:
„A mesterséges intelligencia története 1956. június 18-án vette kezdetét, egy hétfői napon.”
Ezen a napon kezdődött ugyanis egy nyolchetes workshop Hanoverben (USA-ban egy „n”-nel írják), a Darthmouth College kampuszán, amelynek a mesterséges gépek előállítása volt a célja. A műhelyt John McCarthy, a fősuli becsvágyó fiatal tanársegédje szervezte. Ez még az a kor volt, amikor éppen csak elkezdték szélesebb körben is használni a komputereket. (A legendás IBM 650-est ’54-ben dobták piacra.)
International Panic Day
Ez a nap (06.18.) egyébként a pánik nemzetközi napja (Panic Day) is, ahogy a szerző szellemesen felhívja könyvében a figyelmet erre az összefüggésre. Persze rögtön szóba jön egy, e blog elnevezésében is szerepet játszó könyv, DNA (Douglas Noel Adams) Galaxis útikalauz stopposoknak című alkotása, melyben az említett csillagközi útikalauz borítóján a Don’t Panic (Ne pánikolj!) felirat látható. (Továbbá az Elon Musk által a világűrbe kilőtt Tesla Roadster műszerfalán is e mondat virít.) BTW: Musk, ahogy én is, illetve egy másik kultikus brit sci-fi író Arthur C. Clark, imádjuk az említett négyrészes trilógiát (sic). Gyermekkorom másik nagy sci-fi szerzőjét, (amikor még a science tag is erős volt, nem csak a fiction) Isaac Asimovot is érdemes e helyütt megemlíteni.
Persze Walsh teret ad a mesterséges intelligenciához szorosan kötődő robotika világának is, részletesen mutatja be a híres modelleket. Még a Galaxis útikalauz paranoid androidjának, Marvinnak az idézeteivel is színesíti könyvét, az én legnagyobb megelégedésemre. (BTW: ha nem akartok ilyen hosszú szövegeket olvasni, ne pánikoljatok, hanem böngésszétek bátran Marvin hétfői rövid idézeteit itt, a B42-őn.)
BackRub, alias Google
Egyébként az említett, e könyv szerzője által személyesen ismert John McCarthy alapította 1962-ben a legendás Stanford AI Laboratóriumot (SAIL), amely még 2005-ben bemutatott egy önvezető autót (Stanley), továbbá ebből a laborból indult még 1996-ban az a kevéssé ismert, BackRub nevű cég, amely az AI segítségével indított kereséseket a neten. 1997-ben átkeresztelték ezt a vállalatot és onnantól az új nevük Google lett.
Arisztotelész, szimbolikus rendszerek, gépi tanulás
A korábban említett Darthmouth workshop legjelentősebb eredménye két egyszerű, de fontos felismerés volt.
E két pont határozta meg az AI két legfőbb korszakát: a korai szimbolikus szisztémák és később, a ’90-es évektől a gépi tanulás korát. Az elsőben az AI a sakk, go és egyéb társasjátékokban bizonyított, a másodikban már a valódi önfejlesztésben. (Lásd a korábban említett Anthropic példát, miszerint a vállalat élesített szoftverkódjának (production codebase) több mint 80%-át már maga a Claude mesterséges intelligenciájuk írta.)
A szimbolikus AI (más néven GOFAI – Good Old-Fashioned AI) az emberi gondolkodás logikai modellezésére épül. Szabályokra, szimbólumokra és formális logikára támaszkodik, nem pedig statisztikai mintázatokra. Kifejezett emberi utasításokból, „ha-akkor” (if-then) szabályokból és tudásbázisokból építkezik. Működése átlátható; a rendszer pontosan meg tudja indokolni a döntéseit, ellentétben a mai mélytanulási (Deep Learning) modellekkel.

Hat ötlet, hat fejezet
A könyv szerzője, Toby Walsh hat olyan ötlettel/fejezettel ismerteti meg az olvasókat az oldalakon, amelyek közelebb visznek minket az AI megértéséhez.
A válaszok keresése
Az i.e. 3. században Arisztotelész volt az első, aki előállt egy szimbolikus logikával. Híres szillogizmusa szerint: „Minden ember halandó, Szókratész ember, tehát Szókratész halandó.” E példában az „ember”, a „halandó” és a „Szókratész” szimbólumok. (Persze szillogizmusok már korábban is léteztek, pl. ókori indiai szanszkrit szövegekben is fellelhetőek.) A szimbólumok alapvető jelentőséggel bírnak az AI számára, hiszen az intelligencia szoros összefüggésben áll a nyelvvel. A szimbólum-lehorgonyzás probléma (Symbol Grounding) tehát abban áll, hogy miként kötjük a szerveren „unatkozó” szimbólumot ahhoz, amit a való életben reprezentál. (Avagy miként lehet hasznos módon manipulálni a szimbólumokat?)
A legjobb lépés
Versenyhelyzetben (de persze nem csak ott) mindenki a legjobb lépés megtételére törekszik. Esetenként a döntés rengeteg ágú keresőfát eredményez. (Gondoljatok pl. a dámára, a pókerre, az ostáblára, a sakkra és főleg a góra, vagy a tőzsdére.) A szerző egyébként sokféle társasjáték, AI általi elsajátításáról számol be részletesen. Fontos módszer a „visszafelé haladó gondolkodás”, a legtöbb sakkprogram is ezen az elven alapul. (A lehetséges sakkjátszmák összességét egyébként Shannon-számnak nevezzük, amely szám valahol 10¹¹¹ és 10¹²³ között lehet.) Persze hamar kilyukad a szerző is a régi gondolathoz, miszerint az élet is egy játék…
Szabálykövetés
A szűk és speciális szakterületeken az emberi szakértelem egyszerű szabályok követésével szimulálható. Mindez az előző két pontra adott válaszként is felfogható, avagy hogyan találja meg az AI a megoldást az adott problémára. Ezért fontos a problématerület leszűkítése az AI számára. A komputerek korábbi négy generációját a hardver határozta meg. Az első generációs komputerek alapja a vákuumcső volt. A második generációsoké a tranzisztor, a harmadik generációsoké az integrált szilícium áramkör, a negyedik generációs gépeké a mikroprocesszor. A japánok még a ’80-as évek elején egy olyan szuperkomputert akartak építeni, amelyben már nem a hardver, hanem az AI határozta volna meg a működést. (Ez akkor végül sem nekik, sem az őket követő országoknak sem sikerült.)

Mesterséges agyak
Az emberi tanulás roppant komplex folyamat és az agyban megy végbe, ezért hamar megszületett a mesterséges agy megalkotásának igénye is. Az elgondolás az volt, hogy az emberi agy modellezhető olyan mesterséges neuronok hálózatával, amelyek már tanulni is képesek. (Persze agyunk a „legbonyolultabb” szervünk, ráadásul a milliárdnyi neuron működését sem értjük igazán.) Ez persze nem szegte kedvét Walter Pittsetnek és Warren McCullochotnak, akik még a ’40-es években fektették le a digitális neurális hálózatok alapjait.
Az emberhez hasonlóan tanuló gép gondolata is már régen foglalkoztatja a szakembereket. Már (az Enigmát feltörő) Alan Turing is elmélkedett erről annak idején. (BTW: Karácsonykor „botlottam bele” a családommal tök véletlenül Turing szobrába Manchesterben, a Gay Village városrész Sackville nevű kis parkjában. Egyébként az ötven fontoson is az ő arcképe látható.) Végül aztán csak a 2010-es években lendült be igazán a mélytanulás (deep learning) megvalósítása. Ekkor már elég gyors komputerek és sokkal nagyobb adathalmazok váltak hozzáférhetővé, illetve a hiba-visszaterjesztés (backpropagation) algoritmusa is rendelkezésre állt.
Utóbbi algoritmust pedig a GPU-k használata tette hatékonyabbá, melyre egy bizonyos Alex Krizhevsky jött rá. (Vett vajon Nvidia részvényt akkor?) Ezeket a grafikus processzorokat korábban leginkább csak a játékipar használta 3D-s megjelenítésre. Így tulajdonképpen óriási szerencséje volt az említett Nvidia cégnek az AI ipar robbanásszerű grafikus proci igényének megjelenése miatt, értéke egybillió dollárral (!) emelkedett az AI láz féktelen GPU étvágya miatt.
A siker jutalmazása
Ahogy a szerző írja: „Tanulhatunk a tapasztalatainkból, ha jutalmazzuk a sikert, és büntetjük a kudarcot.” Ez maga a megerősítő tanulás. Biciklizni is így tanulunk meg. A kérdés nyilván az, miként tud így tanulni az AI is? A dolgot az teszi bonyolulttá, hogy miként azonosítjuk pl. egy sakkjátszmában a sikeres lépéseket a végkifejlethez képest.
Deepmind
Itt jön képbe a ma már a Google tulajdonában álló Deepmind nevű cég, amelyről és vezetőjéről Sir. Demis Hassabisról ebben a szövegemben olvashattok részletesen. A vállalat, 2010-ben amikor megalakult, megerősítő tanulás segítségével 49 régi Atari videójátékot tanít(tat)ott meg az AI-nak. A mesterséges intelligencia kutatók megdöbbentek a végeredményen! Főleg azon, hogy a program úgy tanulta meg nulláról magas szinten a játékokat, hogy sokat játszott önmaga ellen.
Alphago vs I Szedol
2016 márciusában a Deepmind által fejleszte(te)tt AlphaGo nevű program pedig már 4:1 arányban legyőzte I Szedolt, a 9 danos dél-koreai gomestert! (Fontos tudni, hogy a 2000 éves kínai társasjáték sokkal összetettebb, mint a sakk, és Kínában kiemelt kulturális jelentőséggel bír, egyike a négy művészeti formának, amit egy tudós főnek el kell sajátítani.) Az IBM-féle Deep Blue még 1997-ben győzte le Garri Kaszparovot, ebből is látszik, hogy a go jóval egy komplexebb játék a sakknál. A sakkban általában 20-30 lépés közül választhatunk, a góban ez a szám kb. 200! Ha két lépésre előre gondolkodunk, máris 200×200-ról, vagyis 40.000 lehetséges lépésről beszélünk, három lépés esetén pedig már nyolcmillióról! (Ráadásul a góban nehéz megmondani, hogy ki áll éppen nyerésre.)
RLHF, Reinforcement Learning from Human Feedback
Magyarul emberi visszajelzésen alapuló megerősítő tanulás. Ez kellett ahhoz, hogy a GPT-3-tól eljussunk a ChatGPT-hez. Ez a folyamat nagyjából azt jelenti, hogy az adott modell betanulása során van egy olyan szakasz, amikor hús-vér emberek döntenek arról, hogy a nagy nyelvi modell két outputja közül melyik a pontosabb. Ez a visszacsatolás persze idő- és pénzigényes folyamat, cserébe viszont radikálisan javítja a nyelvi modellek teljesítményét. (Karen Hao sokat foglalkozott a könyvében ezeknek az embereknek az éhbérért való dolgoztatásával, itt tudtok erről olvasni.)
Érvek, hitek, meggyőződések
Thomas Bayes (1701-1761) tiszteletes öröksége
Ebben az utolsó pontban a szerző (kissé túlbonyolítva) bevezet minket a 250 éves Bayes-tétel rejtelmeibe. Ez egy valószínűségszámítási modell, amelyet megfogalmazása óta sok cég használ a mai napig. (Ezért landol kevesebb spam a postafiókunkban, ezt használja a Netflix rendszere a filmajánlásai során, sőt, az 1970-es években az USA Haditengerészete e tétel segítségével számolta ki a szovjet atom-tengeralattjárók legvalószínűbb útvonalát.
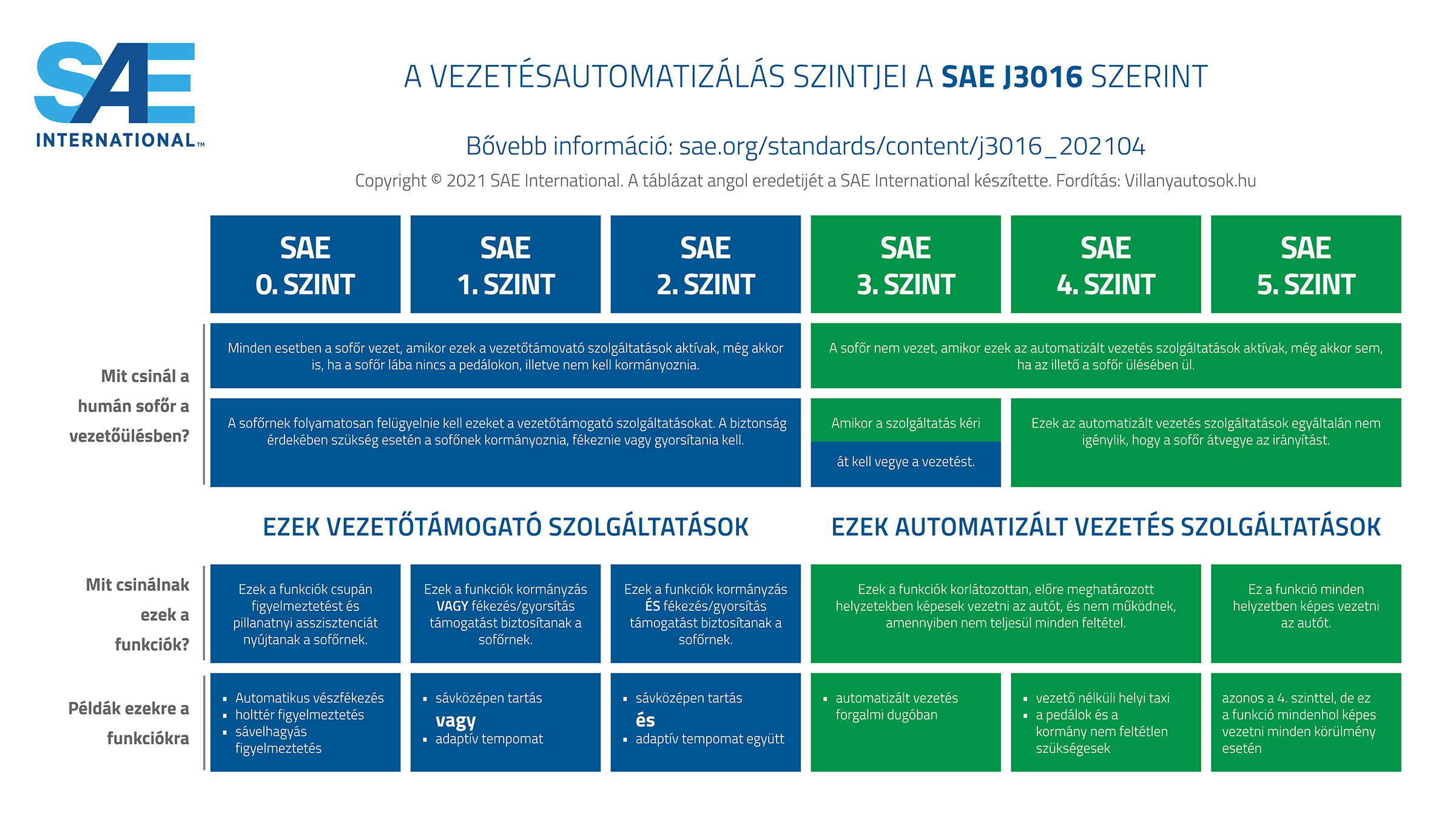
SLAM, Simultaneous Localisation and Mapping
Szimultán helymeghatározás és térképezés. Ez a technika is Bayes tételén alapul. Egyszerre képes frissíteni pl. egy önvezető autó valószínű lokációját, továbbá meghatározni a térképen megjelenő tárgyak helyeztét. Ebben a fejezetben mutatja be a szerző a SAE (Society of Automative Engineers, Gépjáműmérnökök Társasága) öt önvezetési szintjét is.
|
Független portfólió építő felület alkotóművészek és a vizuális művészetek iránt érdeklődők részére.
|
|
Írni, olvasni, fotózni és motorozni szeretek, számolni tudok.
|
|
Kedvelem a jó kérdéseket. Néha fontosabbak, mint a válaszok.
|
|
A magazin 2010-ben indult, fiatalokhoz szóló, független kulturális portál.
|
|
A stílusos élet fontosságának hirdetése.
|
|
Olvasni jó, a könyvet továbbadni kúl.
|
|
Mindegy honnan jössz, a lényeg, hogy tudd hová tartasz, és míg odaérsz, légy jobb minden nap.
|
|
Színész
|
|
Hegymászó
|
|
Head of Innovation
|
|
biztosítóalapító
|
|
A kisnyugdíjas ahol tud, segít.
|
|
Kaotikus életet élő, szentimentális motorkerékpár-őrült.
|
|
Ha pokolra jutsz, legmélyére térj: az már a menny. Mert minden körbe ér.
|
|
Tizennégyszer láttam a Keresztapa-trilógiát.
|
|
Zenét hallgatok/készítek.
|
|
Stylist
|
|
Lakberendező
|
|
Vitorlázó
|
|
Stylist
|
|
Szinteld magad a világra, légy magasabb, mint az árja.
|
|
Az vagy, amit nézel.
|
|
Hegedűs Ágota
|
|
Grafikus, belsőépítész.
|
|
Creative Image Artist
|
|
Büntetőbíró, majd mindenféle szöveg író.
|
A weboldalon cookie-kat használunk, amik segítenek minket a lehető legjobb szolgáltatások nyújtásában. A süti hozzájárulásokat az alábbi menüpontokban kezelheti.
